前两天偶然看到一篇idea非常简单有效的用于定位图片判别性区域的paper,来自MIT大神Bolei Zhou,做了一个简单的实现,发现确实work,在此做个简单分享。
论文尝试解决的问题个人觉得非常有意义,就是在只有image-level label而没有类似detection、segmentation的标注时,我们该如何发现图片中对分类起决定性的那些判别区域。例如我们用ResNet对一张图片进行分类,输出结果显示有99%的概率这张图片里有一只熊猫,那么有没有办法可以告诉我们到底这只熊猫处在图片的哪个位置?
下图给出了一个更加具体的例子,即我们到底可以从图中哪里识别出“刷牙”、“砍树”的action?

Class Activation Mapping
这篇论文所提出方法的核心思路在于通过CNN中最后一个卷积feature map后的Global Average Pooling(GAP)层,把那些用于Softmax分类但却已经失去spatial信息的一维特征向量在各个类别上的response映射回带有spatial信息的feature map上去。
以GoogleNet为例,在用于Softmax分类的全连接层前,是一个能够把1024*7*7的feature map转化成1024维特征向量的GAP层,很显然这个特征向量通过softmax的全连接层后就可以得到原图片在各个类别上的响应。
这里我们用 \(f_k(x, y)\) 表示卷积feature map在坐标 \((x, y)\) 处、通道k的响应值,那么经过GAP后,通道k的响应值就变成了 \(F_k = \sum_{x, y}f_k(x, y)\) ,再继续通过任意一个类别c的全连接层后 \(S_c=\sum_kw_k^cF_k\) ,该类别最后的分类概率也就是 \(P_c = \frac{\exp{S_c} }{\sum_c\exp{S_c} }\) ,注意,上述公式中的系数和bias项均被省略。
现在如果我们再仔细分析一下这个 \(S_c\) ,可以发现
\[S_c=\sum_kw_k^c\sum_{x, y}f_k(x, y)=\sum_{x, y}\sum_kw_k^cf_k(x, y)\]注意,调换顺序后公式的含义是:整个图片的分类响应等于feature map各个空间位置特征的响应之和,而这些空间位置是可以映射回原图片的各个区域的,比如当前GoogleNet的feature map大小是7*7,那么相当于是把原图分成7*7的网格,分别求取每个网格对类别c的响应后再求和,只要能够计算出 \(M_c(x, y)=\sum_kw_k^cf_k(x, y)\) ,也就相当于得到了图像各个区域的判别性热力图!下图对这一过程给出了更加形象的说明。
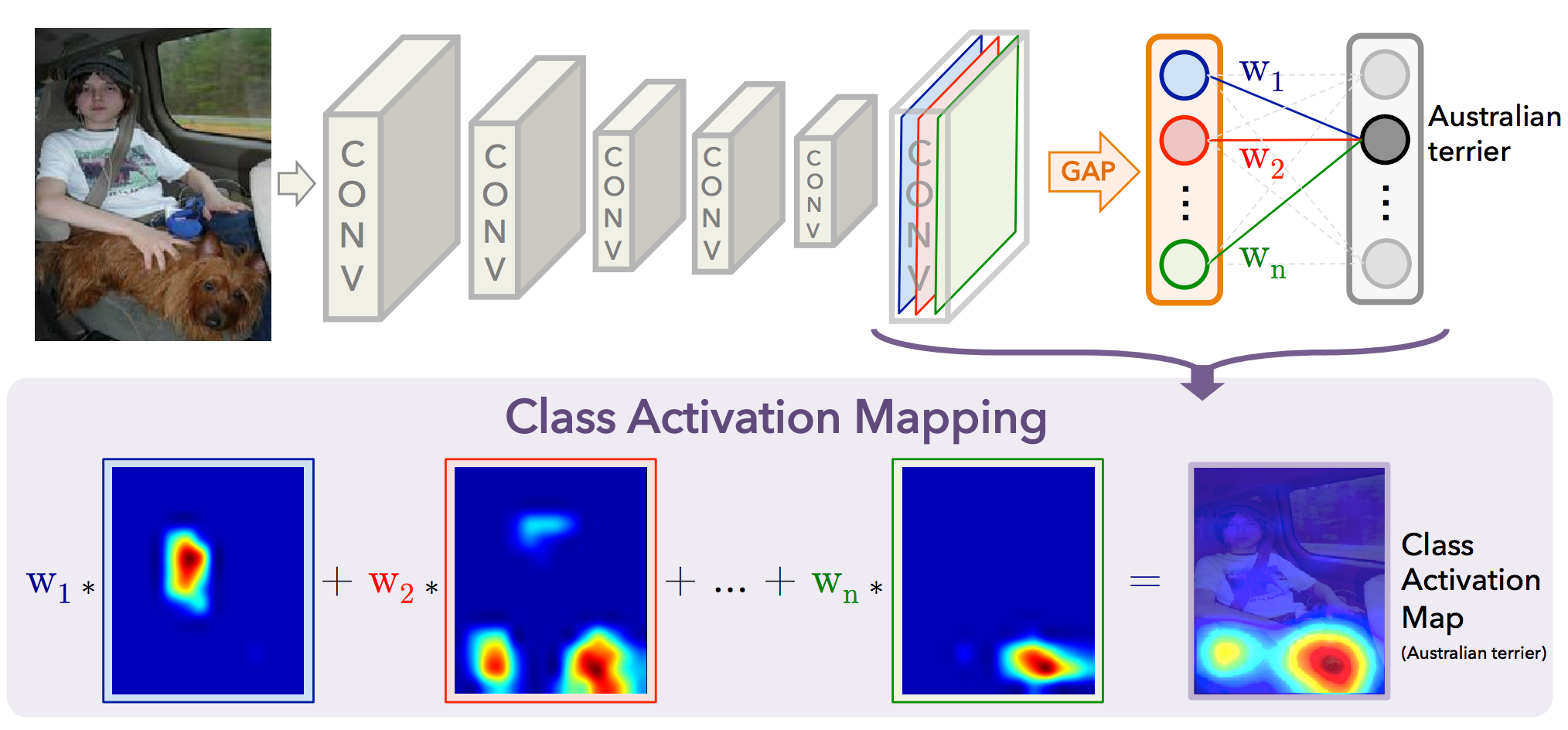 这个idea在实际实现时也非常简单,把图片forward一遍,然后再把分类权重和分类响应做个乘法即可,论文作者给了Matlab的代码,其中还包括一些其它的实验代码,可能看起来比较复杂,所以自己用MXNet对核心方法做了个简单实现,代码已提交到MXNet的master分支里,详情请点击这里。
这个idea在实际实现时也非常简单,把图片forward一遍,然后再把分类权重和分类响应做个乘法即可,论文作者给了Matlab的代码,其中还包括一些其它的实验代码,可能看起来比较复杂,所以自己用MXNet对核心方法做了个简单实现,代码已提交到MXNet的master分支里,详情请点击这里。
Video CAM(Update)
今天又把这个idea在视频分类上做了一个应用,效果也非常不错,下面几幅图片展示了一些例子:
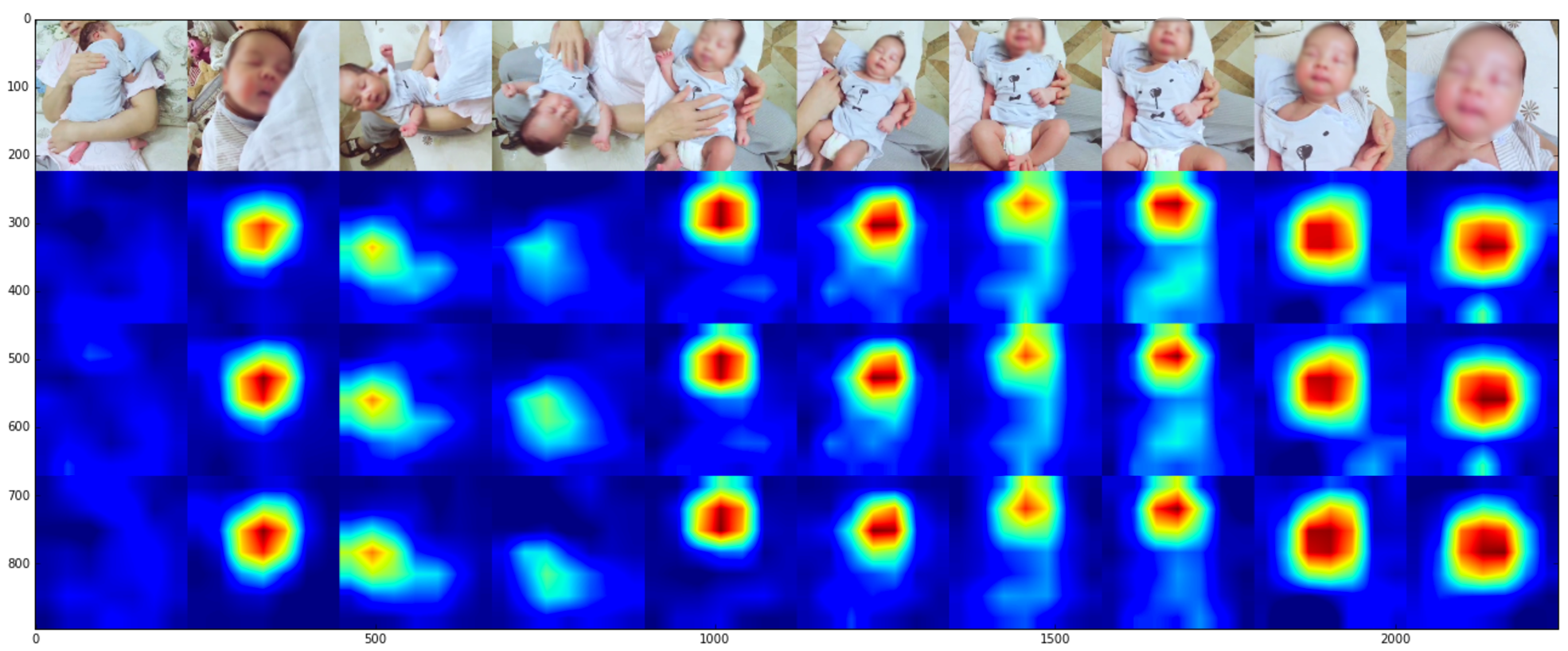

需要注意的是,这里所使用的视频分类网络是真正的video-level classification,而不是把每帧图片做图片分类,具体实现的方法与图片分类模型类似:在训练阶段,假设每个batch视频数量为N,每个视频所抽取的视频帧数量为L,特征维度为C,feature map分辨率为H*W,那么我们只需要把原来图片(N, C, H, W)三维的feature map换成视频(N, C, L, H, W)四维的feature map,再按照论文所述方法通过GAP转化成(N, C)的视频特征向量,接上一个softmax分类即可;在inference阶段(求CAM),同样用分类器weight与每个视频shape=(C, L, H, W)的feature map相乘即可获得其同时包含temporal和spatial信息的discriminative heat cube了。
