简介
自从Gatys在2015年在Arxiv挂出一篇使用Deep Learning进行艺术画风格学习的文章[1]后,Style Transfer就成为了学术界和业界一个非常火的问题,凭借这个idea产生的移动端应用Prisma也是风靡全球,不过非常神奇的是,以往Paper更新速度奇快的CV领域,居然在2015年的后半段几乎没有新的效果好的idea出现,直到今年三月,来自俄罗斯斯科尔科沃科技学院(SkolTech)的Dmitry Ulyanov和来自斯坦福视觉实验室的Justin Johnson分别发布了一篇论文[2, 3],相比Gatys原有的方法具有较大的创新,并且解决了每幅图片都需要重新训练这一严重影响效率的问题,从此,实时风格转移成为了可能,再随后,Dmitry Ulyanov还提出了Instance Normalization[4]这一用于替换Batch Normalization的改进,在不需要改变原有框架的情况下,非常神奇的再次提高了生成图像的质量。最近,谷歌的工程师在此基础上又做了少许更改[5],实现了通过一个网络模型同时生成N种风格图像的目标,引发轰动,下面我们从头开始对这一系列方法进行介绍。
数学化的图像内容与风格描述
Gatys的这篇文章[1]可以算是Neural Style这一系列方法的开山之作,后续的各种方法也都是围绕其核心思想在具体实现上进行改进,重要性不言而喻。Style Transfer这个问题可以定义为:把风格图像 \(X_s\) 的绘图风格融入内容图像 \(X_c\) ,得到一副新的图像 \(\hat{X}\) (Style transfer is the technique of recomposing images in the style of other images)。作者认为图片风格转移这一问题可以通过两个操作来实现:保持原图像的内容,融入风格图像的底层视觉特征。前者是指如果给定的内容图像画的是一只长颈鹿,那么转换后的图像还得是一只长颈鹿,不能变成猫、狗或者其他任何物体;后者是指虽然梵高的《星空》和长颈鹿并没有什么关系,但必须让修改后的这只长颈鹿具有《星空》里那种特有的风格(笔触、色调等)。不过如果只有这样概念性质的方法描述显然不够,因为前人早就已经有过类似的idea,得把它转化成数学公式才是王道,个人认为Gatys的此篇Paper最大的贡献就在这里,即用定量化的数学公式对艺术画的“风格”进行描述,并给出一个基于深度特征的图片间风格相似度评价方法,要知道在此之前,我们基本上是没有任何标准数学评价方法来判定两幅画是否风格相似的。
在CNN的不同网络层中,目前公认的观点是底层特征比较接近传统low-level视觉特征,而高层特征是比较抽象的图像内容描述,因此很自然的我们会想到可以通过计算两幅图像CNN高层特征相似度的方法来评价其内容相似度,假设 \(P^l, F^l\) 分别是两幅图像 \(p, x\) 在某个CNN网络第l层的feature map, \(F^l_{ij}\) 表示第i个filter产生的feature map的第j个元素,其中 \(i\in[1, N_l], j\in [1, M_l=\text{width}\times\text{height}]\) ,那么定义两幅图片content的差异度函数:
\[L_{\text{content} } = \frac{1}{2}\sum_{i,j}(F_{ij}^l-P_{ij}^l)^2\]既然我们用了高层CNN特征作为图像content相似度的评价函数,那么图像style是不是可以用底层CNN特征进行类似的定义呢?答案是对了一半,与传统low-level视觉特征相似的底层CNN特征虽然在已定程度上是包含了图像的风格特点,但是因为feature map的spatial信息过于显著,如果直接计算其欧式距离可能会因为这个原因产生非常大的误差(想象一下两幅style相似但是content完全不同的图像),因此需要想办法在保留这些low-level视觉特征的前提下把spatial信息消除掉,Gatys在提出了一个非常神奇的Gram矩阵:
\[G_{ij}^l = \sum_{k}F_{ik}^lF_{kj}^l\]通过这个公式计算出的图像在第l层的Gram矩阵 \(G \in R^{N_l \times N_l}\) ,不在包含任何spatial信息,只与feature map的filter数量有关。现在我们再用上面类似的方法来定义style差异度函数,假设G和A分别是在图像 \(p, x\) 上得到的Gram矩阵,那么
\[L_{\text{style} } = \frac{1}{4N_l^2M_l^2}\sum_{i,j}(G_{ij}^l-A_{ij}^l)^2\]到此为止,我们已经可以利用一个CNN网络来对任意两幅图片进行Content和Style的相似度评价,
\[L_{\text{total} } = L_{\text{content} }+\alpha L_{\text{style} }\]并且根据上面的公式可以很容易的得到对应变量的梯度信息,这一点为后续进行实际的图像风格转移操作提供了可能。
基于迭代的风格转移
虽然本篇的重点在于基于FeedForward网络的快速风格转移算法,不过为了文章的完整性,这里也简要介绍一下Gatys论文中所给出的基于迭代的风格转移算法。
为了把一幅Style图像a的风格转移到另一幅Content图像p上得到一个新的图像x,我们实际上需要通过某种方法使得x和p的Content相似而x和a的Style相似,用数学公式表示就是要最小化如下函数:
\[L_{\text{total}(p, a, x)} = L_{\text{content} }(p, x)+\alpha L_{\text{style} }(a, x)\]Gatys给出的idea是先用随机noise初始化x,然后不断通过计算上述函数关于x的梯度来更新x,最后得到我们想要的风格图像。这个方法需要注意的是:a) 更新的参数并不是CNN网络,而是输入的数据x;b) 损失函数并不像一般的Softmax、Linear Regression之类可以在一个网络层中实现,而是需要把一个完整的已经预训练过的图像识别CNN与上述损失函数配合;c) 由于随机初始化的原因,每次得到的最终结果可能有一定差异;d) 由于此方法每次都需要重新训练,因此速度较慢,很难做成实时应用。
基于FeedForward网络的快速风格转移
2016年三月,来自俄罗斯斯科尔科沃科技学院(SkolTech)的Dmitry Ulyanov和来自斯坦福视觉实验室的Justin Johnson分别发布了一篇论文[2, 3],号称实现了不用每次迭代训练的实时FeedForward风格转移算法,不过非常有趣的是虽然两篇paper都是他们各自的独立工作,但是idea几乎完全一致,只在一些实现细节上存在差异,个人推测他们应该都是从最近大热的GAN中得到了灵感,然后立马coding进行实现,最后paper完成的时间基本一致。
闲话不多说,还是回到算法上来,两位作者提出的算法框架如下:
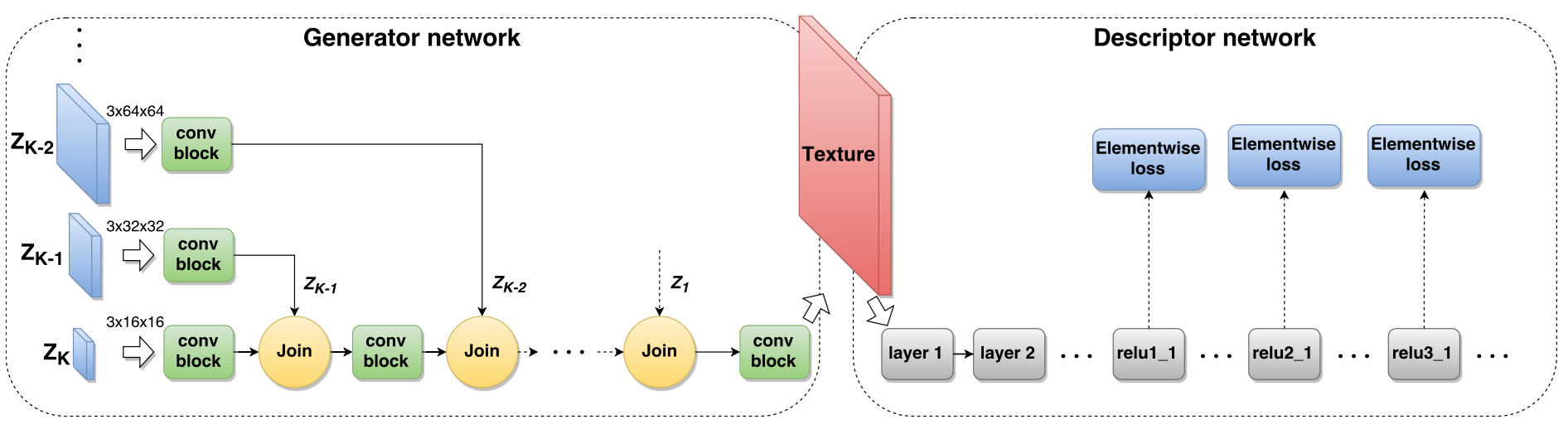 从图中可以看到,相比原方法这里多出了一个专门用于风格转移的CNN生成网络,而通过引入这样一个类似于GAN中生成器(Generator)G的网络,我们可以回到传统Deep Learning方法off-line训练+on-line预测的模式,测试阶段整个网络不用再反复迭代,只需前向传播一次即可,大大加速了风格转移的速度。
从图中可以看到,相比原方法这里多出了一个专门用于风格转移的CNN生成网络,而通过引入这样一个类似于GAN中生成器(Generator)G的网络,我们可以回到传统Deep Learning方法off-line训练+on-line预测的模式,测试阶段整个网络不用再反复迭代,只需前向传播一次即可,大大加速了风格转移的速度。
整个网络的优化目标和之前保持不变,都是最小化 \(L_{\text{total} }\) ,发生改变的是损失函数产生的梯度(上图中Descriptor Network产生的梯度)不再直接用来更新图片x,而是更新用来生成x的Generator网络,另外,该生成器并不像GAN中的生成器那样只输入一个随机噪声,而是输入Content图像p,这样的好处是生成器G可以直接获得图像最原始的各种信息,需要做的只是学习一个Style Transform Function,不像Gatys的方法那样需要从随机噪声开始不断同时猜测(优化)Style图像的风格和Content图像的内容。
整个方法具体实现起来不算困难,网上有很多开源实现,MXNet版请看官方example。另外值得一提的是Dmitry Ulyanov把这个网络命名为Texture Network而不是类似于Fast Style Transfer Network之类的东西,个人觉得非常有道理,因为从基于Gram矩阵的这一系列方法的结果上看,其实现的功能还是纹理+颜色特征转移,艺术风格的很多其它方面还没有特别明显的体现,在以后可能还有待科研工作者的发掘。
替换BN,使用Instance Normalization
虽然有了Texture Network这个大的方法框架,但是作者Dmitry Ulyanov始终觉得其效果和原始基于迭代的那个方法比起来有些不足,然后找到了一个非常简单但是有效的改进措施,就是把生成器网络G中的所有BN层换成一种叫做Instance Normalization的网络层,该网络层与BN的差别在于:
BN需要在一个mini-batch中计算多个样本feature map的均值与方差,
\[\mu_i=\frac{1}{HWT}\sum_{t=1}^T\sum_{l=1}^H\sum_{m=1}^Wx_{tilm}\] \[\sigma_i^2 = \frac{1}{HWT}\sum_{t=1}^T\sum_{l=1}^H\sum_{m=1}^W(x_{tilm}-\mu_i)^2\]这里i是feature map通道的index,T代表mini-batch的size,H、W分别是feature map的高和宽。
Instance Normalization省略了T这一维度,
\[\mu_{ti}=\frac{1}{HW}\sum_{l=1}^H\sum_{m=1}^Wx_{tilm}\] \[\sigma_i^2 = \frac{1}{HW}\sum_{l=1}^H\sum_{m=1}^W(x_{tilm}-\mu_{ti})^2\]关于这个改进为什么起作用的原因作者在paper中写道:
“A simple observation is that the result of stylization should not, in general, depend on the contrast of the content image (see fig. 2). In fact, the style loss is designed to transfer elements from a style image to the content image such that the contrast of the stylized image is similar to the contrast of the style image. Thus, the generator network should discard contrast information in the content image. The question is whether contrast normalization can be implemented efficiently by combining standard CNN building blocks or whether, instead, is best implemented directly in the architecture.”
简单翻译一下就是风格转移应该忽略Content图像的对比度(contrast),事实上,风格转移的其中一个目标就是把Style图像的对比度转移到新图片上去,因此我们应该在生成器网络G中丢弃Content图像的对比度信息。刚看到这里的时候本人简直懵逼,BN或者Instance Normalization和图像对比度能有啥关系?后来某个深夜洗澡的时候突然灵光一闪,原来这些Normalization操作中对方差的规范化其实就是在消除对比度!原方法的生成器网络G使用BN很大程度上就是为了解决这个对比度适应的问题,但因为样本差异性可能非常大,而BN会跨样本计算均值和方差,所以这样计算出的数值对每个样本来说可能不够准确;作者提出的这个限制在每个样本内部的Instance Normalization则不同,完全就是针对每个样本的去对比度操作,因此最终产生了非常棒的性能提升!
再进一步,一个Model,N种风格
终于到Google Brain最近”A LEARNED REPRESENTATION FOR ARTISTIC STYLE”的这项“微小”工作了,这篇文章本质上其实还是在Normalization这个点上做文章,上面提到的生成器网络中不管是原本的BN还是改进的Instance Normalization,在把样本根据其均值方差规范化后都还有一个附加的scale+shift操作,
\[z = \gamma\frac{x-\mu}{\sigma}+\beta\]作者认为不同Style Transfer操作的差异性其实并不在各种卷积操作上体现,而在于这些Normalization层中的scale+shift操作上,所以对于不同风格的转移模型,我们是可以通过参数共享的方式把它们融入一个模型中的!具体来说,我们需要把上面scale+shift操作中的 \(\gamma, \beta\) 在feature map通道数C的基础上再扩展一个维度,这个新的维度则可以用于模拟不同的艺术画风格,例如对于第 \(n\in[1, N]\) 种艺术风格,
\[z_n = \gamma_n\frac{x-\mu}{\sigma}+\beta_n\]好吧,还真是一个“微小”的工作,下面是作者给出的应用这个方法后某一单一网络模型得到的风格图片,不得不说还真是很逼真?。

总结
Neural Style系列方法发展到今天,从最开始非常低效的逐图迭代方法到现在的快速FeedForward模型可以说进步非常巨大,也让实时视频风格渲染成为了可能,不过另一方面关于图像风格的数学化描述目前还是只有那个神奇的Gram矩阵,到今天也没有出现描述能力更强的idea,Deep Learning在艺术领域的应用在未来应该还会有非常大的发挥空间。
Reference
[1] Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. “A neural algorithm of artistic style.” arXiv preprint arXiv:1508.06576 (2015).
[2] Ulyanov, Dmitry, et al. “Texture Networks: Feed-forward Synthesis of Textures and Stylized Images.” arXiv preprint arXiv:1603.03417 (2016).
[3] Johnson, Justin, Alexandre Alahi, and Li Fei-Fei. “Perceptual losses for real-time style transfer and super-resolution.” arXiv preprint arXiv:1603.08155(2016).
[4] Ulyanov, Dmitry, Andrea Vedaldi, and Victor Lempitsky. “Instance Normalization: The Missing Ingredient for Fast Stylization.” arXiv preprint arXiv:1607.08022 (2016).
[5] Vincent Dumoulin, Jonathon Shlens, Manjunath Kudlur. “A Learned Representation For Artistic Style.” arXiv preprint arXiv:1610.07629 (2016).
