论文:Stacked Attention Networks for Image Question Answering(CVPR 2016)。
这篇来自CMU的文章主要研究的是Image Question Answering的问题,且是CVPR 2016第一个session的oral,虽然这次去开会一路听人吐槽现在CV完全就是DL灌水活动,但是不得不说深度学习技术让我们可以开始尝试很多以前不太敢想的新问题,这一点在计算机这种应用科学领域中显得尤为重要,而这篇关于Image QA的文章就是一个很好的例子。
Image QA的问题定义其实非常清晰,就是给定一张图片与一个问题描述,让计算机预测问题的答案。当然,这里所说的问题必须是能够直接从图片中推理得到答案的类型,而不是某些与图片无关或者过于抽象的问题,例如对下图提问”What are sitting in the basket on a bicycle?”
 我们希望能够通过某个模型得出答案”dogs”。可以看出,Image QA其实是一个NLP和CV的综合性问题,模型需要同时分析问题的含义和图片的内容,随着问题的不同,其难度也随之变化。
我们希望能够通过某个模型得出答案”dogs”。可以看出,Image QA其实是一个NLP和CV的综合性问题,模型需要同时分析问题的含义和图片的内容,随着问题的不同,其难度也随之变化。
一种比较容易想到的方法是:a) 对问题语句用W2V、LSTM等转化成一个向量形式的特征表示;b) 对图片用CNN提取出一个全局特征;c) 结合图片特征和问题特征使用深度网络或者其他模型来对答案做inference。过去几年其实也有一些基于这种框架的paper发表出来,并且取得了一些成果,不过作者认为这种框架很难处理某些需要特殊关注图片局部区域(a set of fine-grained regions in an image)的问题,因为只对图片进行了一个全局特征提取。
以上面”what are sitting in the basket on a bicycle”为例,在回答这个问题时我们实际上需要进行多步的reasoning:1) 定位basket和bicycle;2) 理解sitting in和on的含义;3) 排除无关物体,定位最可能与答案相关的区域;4) 预测答案。为此,文章作者提出了一个叫做stacked attention networks (SANs)的方法,该方法主要包含image model、question model和stacked attention model,分别用于图片内容的特征提取、问题特征提取和针对于问题的multi-step reasoning,整个方法框架如下:
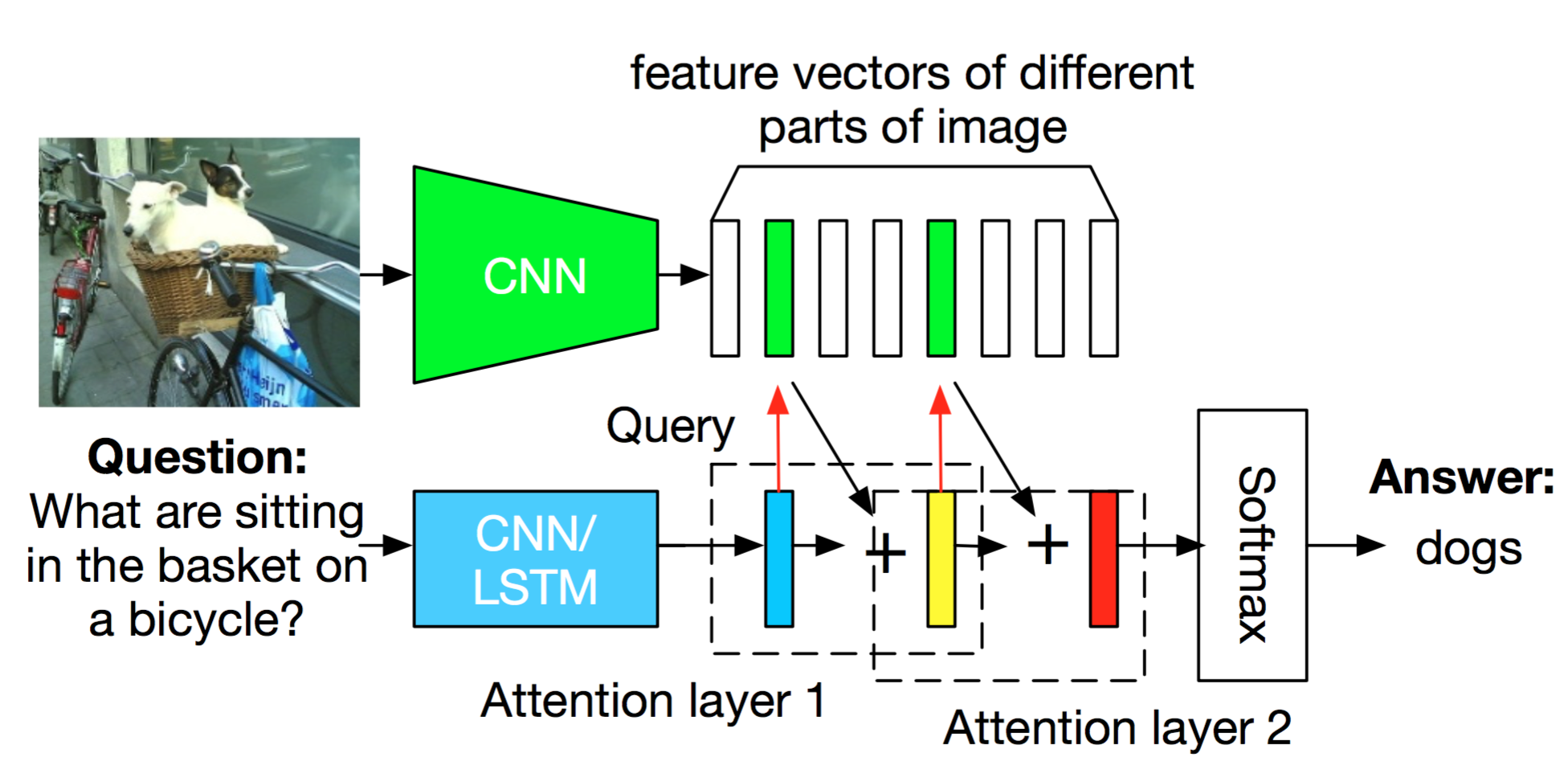
Image Model
作者使用一个输入为 \(448\times 448\) 的VGGNet来对输入图片进行特征提取,不过与过去大部分方法不同的是,这里选择的并不是最后一个fc layer作为特征表示,而是选择依然带有spatial信息的最后一个pooling layer,特征维度是 \(512\times 14\times 14\) ,这里每个512维的特征 \(f_i, i \in [0,195]\) 实际上可以对应到原图一个 \(32\times 32\) 大小的region。然后,为了使最终每个region的特征维度与问题特征相同,作者又在网络后面增加了一个针对每个region的fc layer进行维度变换:
\[v_I=tanh(W_If_I+b_I)\]| 这里 $$I={i | 0\le i\le195}\(是各个region的集合,\)v_i$$ 是针对每个region最终的一个visual feature。 |
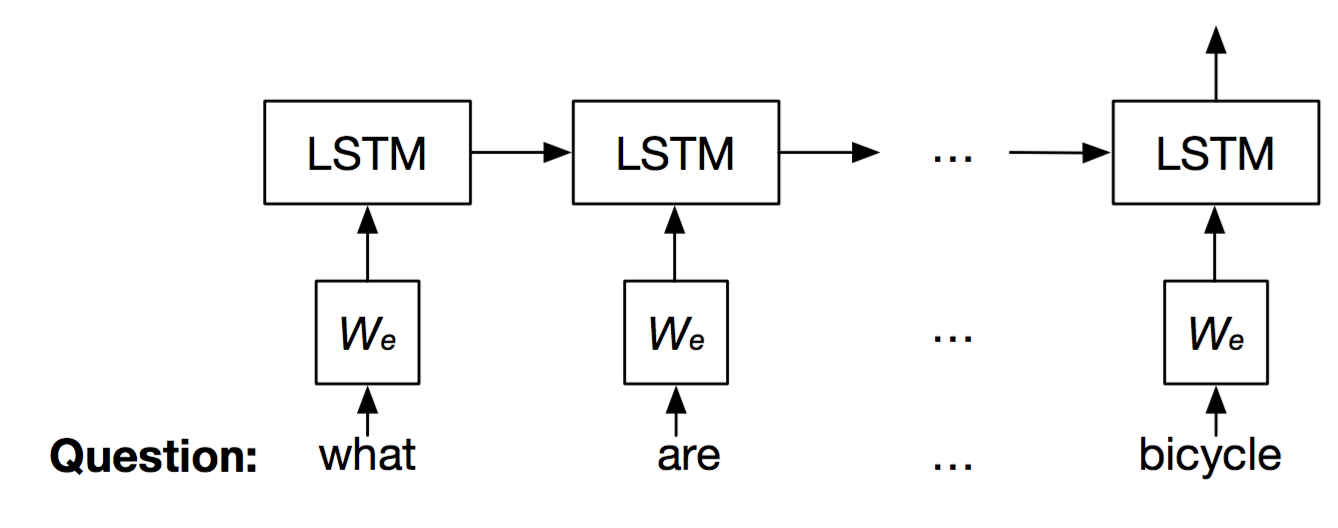
Question Model
根据之前一些NLP领域的研究,LSTM和CNN其实都可以用来文本特征,因此作者在question的特征提取上也分别使用这两种模型,作为对照方法。
对于这两种方法,首先都需要用word2vec把question语句 \(q=[q_1, q_2, \cdots, q_T]\) 转化成向量形式 \(x=[x_1, x_2, \cdots, x_T]\) ,然后输入LSTM或者CNN网络,得到question feature vector \(v_Q\) ,其中LSTM就是标准的LSTM结构,CNN在做卷积时选用了unigram, bigram, trigram三种大小的filter,然后在卷积后通过在时间维度上进行max pooling,使得最终每个句子的特征维度相同。
Stacked Attention Networks
前面的image model和question model其实都算是已有方法的应用,而文章的主要创新点在于特征提取之后基于attention network的multi-step reasoning。作者认为传统使用全局特征的方法由于引入了过多的噪声信息(即不相关区域的特征),导致最终的预测可能会陷入sub-optimal point,为此,新提出了一种利用多个attention layer进行逐级reasoning的方法,这些网络层一步一步剔除不相关区域,最终在精确定位问题所关注物体后才尽兴答案预测。
给定一个图片特征矩阵 \(v_I\) 和问题特征向量 \(v_Q\) ,首先使用一个单层fc layer对图片矩阵的各个region进行attention distribution的预测,
\[h_A = tanh(W_{I,A}v_I\oplus(W_{Q,A}v_Q+b_A))\] \[p_I= \text{softmax}(W_Ph_A+b_P)\]这里 \(v_I\in R^{d\times m}\) ,d是图片特征的维度,m是region个数, \(v_Q\in R^d\) 是question的特征向量,参数 \(W_{I,A}, W_{Q, A}\in R^{k\times d}, W_P\in R^{1\times k}\) , 预测得到各个region的attention distribution为 \(p_I\in R^m\) 。
此时,我们可以通过加权求和得到一个针对问题更加有用的图片特征向量表示
\[\tilde{v}_I = \sum_ip_iv_i\]然后是一个结合图片特征与问题特征的统一特征表示(combined question and image vector)
\[\mu = \tilde{v}_I+v_Q\]与传统的全局特征相比,这里的attention based feature会根据问题的不同而对图片进行有选择性的关注,论文原话是”higher weights are put on the visual regions that are more relevant to the question”。不过作者还考虑到一个attention layer可能不足以捕捉到感兴趣区域在哪,因此使用了串联的multiple attention layer来进行region weight的学习
\[h^k_A = tanh(W^k_{I,A}v_I\oplus(W^k_{Q,A}\mu^{k-1}+b^k_A))\] \[p^k_I= \text{softmax}(W^k_Ph^k_A+b^k_P)\]其中 \(\mu_0\) 被初始化为 \(v_Q\) 。对应的aggregated image feature 和combined question and image vector为
\[\tilde{v}^k_I = \sum_ip^k_iv_i\] \[\mu^k= \tilde{v}^k_I+\mu^{k-1}\]换句话说,其实整个过程是在不断的循环迭代,每次更新一遍 \(\mu^k\) 这个combined question and image vector,然后在最后第K轮使用 \(\mu^K\) 进行答案预测,
\[p_{\text{ans} }=\text{softmax}(W_uu^K+b_u)\]另外,从这个答案预测的设置情况看(都是single word),问题应该都是类似于预测图片某个object的问题。
实验结果
作者在DAQUAR-ALL、DAQUAR-REDUCED、COCO-QA和VQA四个数据集上进行了测试,从实际结果上看,question model中选择CNN还是LSTM差别不是特别明显,在不同数据集上各有高低,然后选择一层attention layer或者两层则差别较为明显,基本选择两层的情况都比一层要好。在作者的进一步分析中,还发现SAN在不同类别问题上表现出相对已有方法的提升也不太一样,比如COCO-QA数据集上关于Color的问题高于Object高于Location高于Number。
不过作者似乎没有把3层attention layer的实验结果present出来,不知道是因为何种原因,毕竟名字叫做Stacked Attention Networks,如果只有两层还是有点奇怪。
