(本文主要参考TVM在arxiv上的论文和官方tutorials)。
说起神经网络模型加速,可能大部分人首先想到的会是KD、剪枝、量化这些模型压缩方法,不过在实际项目中算法研发人员如果已经尝试了各种压缩方案却依然无法满足性能需求的话,我们是否还有其他可以努力的点呢?
一般来说,深度学习计算库本身的计算效率肯定是最先应该被考虑的,事实上,同一个网络在caffe、caffe2、Keras、PyTorch、TF、MXNet等各种框架下如果真正做个benchmark,结果差距或许会大的惊人,就目前市面上大部分人能接触到的免费深度学习计算库而言,如果只考虑在英伟达GPU平台上做模型预测,性能标杆应该还是英伟达自家的TensorRT(因为其他计算框架大多都是调用CUDNN),但如果哪天你又因为业务扩展想支持诸如服务端CPU甚至ARM移动端等,那么接下来针对每个平台又还得再花功夫去寻找其他计算库来做支持,在确保基本功能可以多平台实现的前提下进一步解决不同框架细节上的细微差异,这样的一套跨平台深度学习解决方案绝对是一个非常花费人力、物力的挑战。
本文将会介绍TVM这个模型部署工具如何解决跨平台自动代码生成与硬件加速两个核心问题,并在英伟达GPU平台上给出一些对比实验结果以展示其真实表现。
TVM概览
首先看一下TVM的系统概览图
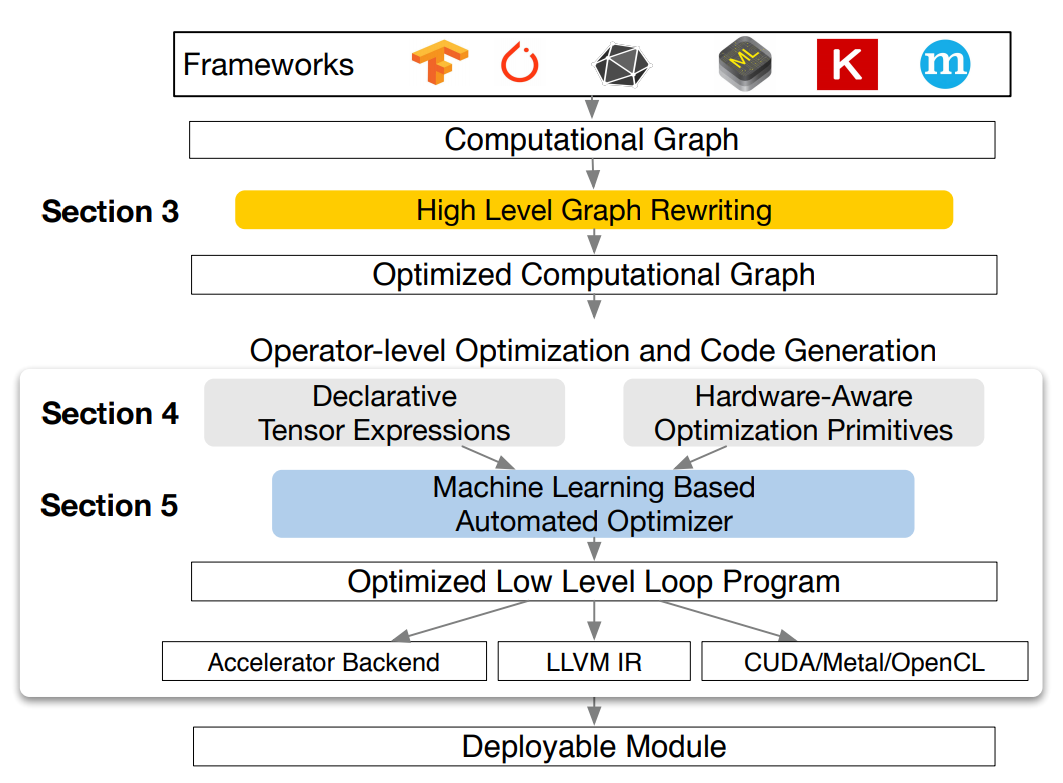
可以看出使用TVM进行模型部署的完整流程包括:
- TF、PyTorch、MXNet等frontend深度学习框架的模型到计算图IR的转换;
- 对原始计算图IR进行graph优化,得到Optimized Computational Graph;
- 对计算图中的每个op获取用tensor expression language描述的Tensor计算表达式,并针对所需的硬件平台,选择最小计算原语(primitives)生成具体的schedule;
- 使用某种基于机器学习的Automated Optimizer生成经过优化的Low Level Loop Program;
- 生成特定于硬件设备的二进制程序;
- 生成可以部署的module;
下面我们自上而下分别聊一聊上述过程的几个核心步骤。
Graph优化
常见的深度神经网络本质上可以看成是一个计算图(computational graph),下图给出了一个两层卷积CNN的例子作为展示
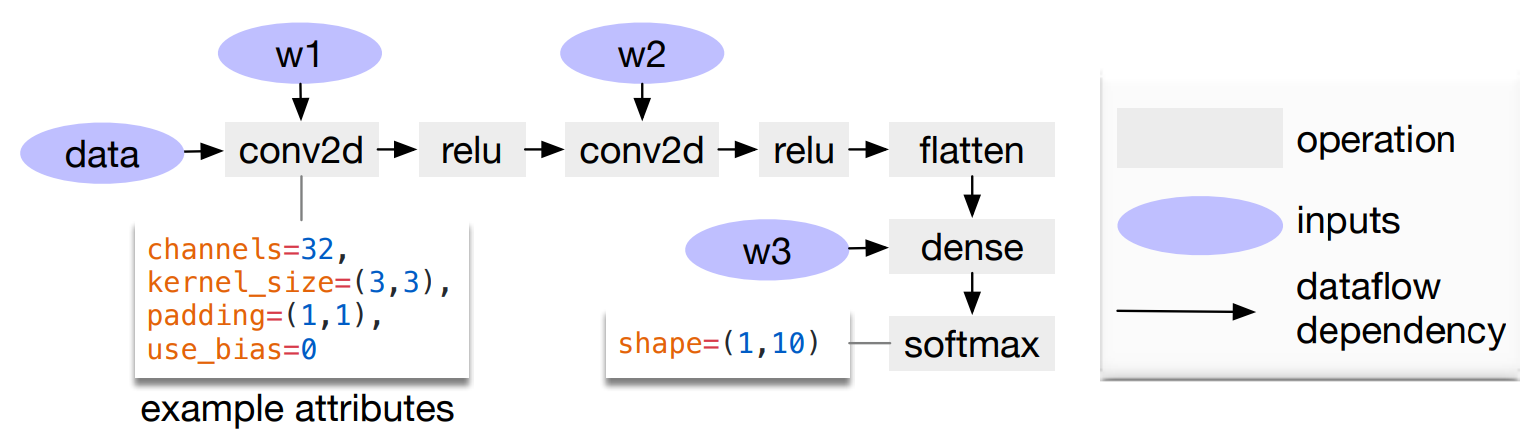
比较早期的时候大家主要把优化精力放在了operator上(例如conv的n种实现),而选择,则慢慢的开始发现其实在graph层面就可以做非常多的改进,TVM在这个层面实现了如下几种
- operator fusion: 把多个独立的operator融合成一个;
- constant-folding: 把一些可以静态计算出来的常量提前计算出来;
- static memory planning pass: 预先把需要的存储空间申请下来,避免动态分配;
- data layout transformations: 有些特殊的计算设备可能会对不同的data layout (i.e. NCHW, NHWC, HWCN)有不同的性能,TVM可以根据实际需求在graph层面就做好这些转换。
后三点其实从定义上看大体都能理解其具体含义,但第一点op fusion对很多人而言可能还是会有些困扰,简单来说,op fusion就是“把原本n个函数调用合并到一个函数里面”,以最常见的conv-bn-relu为例,假设输入为x,如果按照正常的计算流程我们需要做如下操作
x1 = conv(x)
x2 = bn(x1)
y = relu(x2)
可以看到,我们为了得到最终的结果y,需要进行三次函数调用,并且存储中间结果x1和x2,但如果我们进行了op fusion,整个过程则会变成如下形式
y = conv_bn_relu(x)
此时,所有中间计算结果都被省略,计算速度和存储空间同时得到了优化。TVM的作者在论文中对各种operator做了个分类:
- injective (one-to-one map, e.g., add)
- reduction (e.g., sum)
- complex-out-fusable (can fuse element-wise map to output, e.g., conv2d)
- opaque (cannot be fused, e.g., sort)
实际在做op fusion时遵循如下原则
- 任意多个(连续)injective op都可以被合并成一个op;
- injective op如果作为一个reduction op的输入,则可以被合并;
- 如果complex-out op(如conv2d)的输出如果接的是element-wise,则可以被合并;
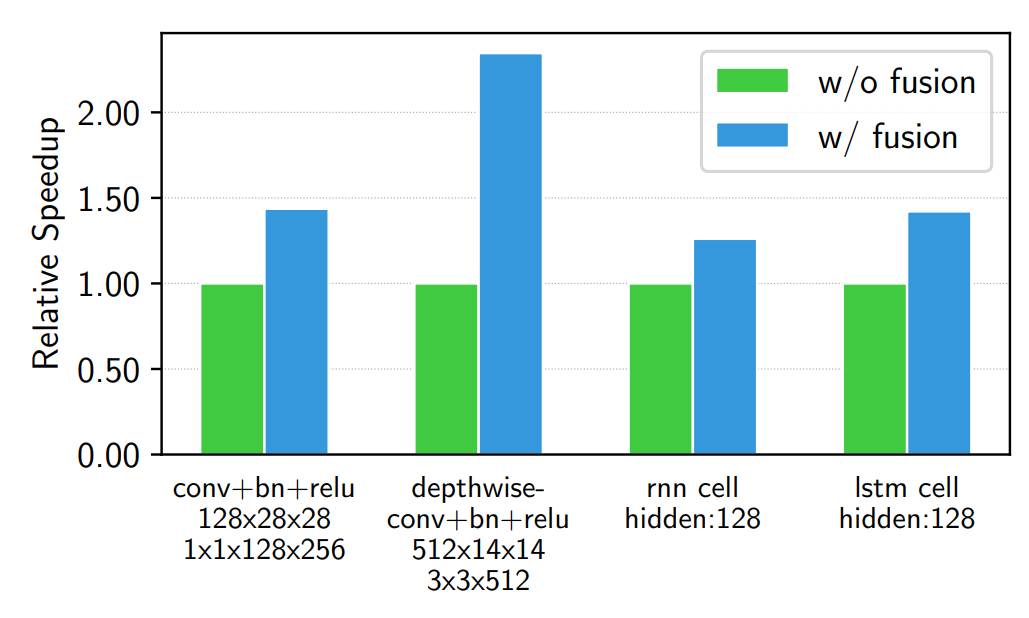
下图展示了一些常见op fusion给网络带来的加速效果:
生成Operator代码
当我们有了计算图的结构,下一步需要考虑的自然是计算图中各种operator的实现,由于各个硬件平台的软硬件差异,导致如今每个平台可能都有各种各样不同的轮子,具体功能、性能的完成质量也是不尽相同,TVM为了解决跨平台operator代码自动生成的问题引入了一种tensor expression language,下面展示了一个用其表示矩阵乘法的例子
m, n, h = t.var('m'), t.var('n'), t.var('h')
A = t.placeholder((m, h), name='A')
B = t.placeholder((n, h), name='B')
k = t.reduce_axis((0, h), name='k')
C = t.compute((m, n), lambda y, x: t.sum(A[k, y] * B[k, x], axis=k))
注意,这种DSL虽然可以用于定义很多常见的数学操作,但并没有指定具体的底层代码该如何实现(比如矩阵乘法计算时先遍历y方向还是先遍历x方向等),这实际上是遵循了“decouple algorithm from schedule(解耦计算方法和具体调度)”这一原则,其中algorithm定义了”what is computed”,schedule则定义了”where and when it’s computed”,举个简单的例子,一个3*3的卷积我们可以有很多种底层代码来进行实现,虽然每一种的计算结果都完全一致,但是具体计算过程可能千差万别。
如上所述,tensor expression language其实只完成了计算algorithm的描述,具体的schedule还有很多种实现方法,这里,TVM定义了几种最细粒度的schedule(统称为schedule primitives),并在各种硬件backends上做了实现,详情如下表所示
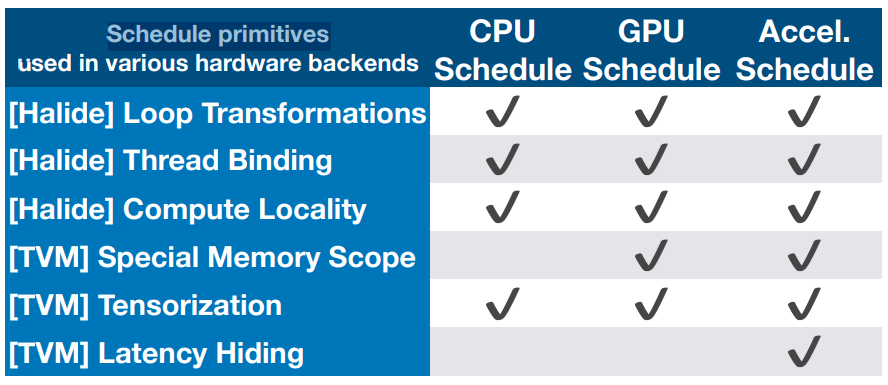
所以TVM对某个operator进行自动代码生成的过程实际上是这样
自动优化
上一节最后我们展示了如何使用tensor expression language和各种schedule primitives来生成底层代码,加上之前介绍的计算图IR,看起来我们已经解决了模型计算的整个问题,等等,刚才我们的确是说了TVM提供了一些schedule primitives,但是究竟如何组合它们来实现一个optimal operator implementation还是一个未知的问题,使用默认的方案自然可以保证结果正确,但是计算效率绝对无法保证,事实上,硬件设备的类型、输入大小、tensor layout等很多种因素都可能会影响一个operator的具体实现是否高效,同时,我们既无法真的针对任意一种情况给出一个最优实现的解析解,也无法暴力遍历所有情况给出一个最优实现的查找表,因此现在我们所用的这些深度学习框架其实都没法100%利用到所给的硬件资源。
TVM为了解决此问题提出了一种利用机器学习来进行自动优化的方案,包含以下两个核心模块:
- Schedule explorer: 用于不断搜寻新的schedule配置;
- Cost model: 用于预测每一种schedule配置的计算耗时;
schedule explorer本质上来说就是我们对搜索空间的定义,TVM允许你通过手工设置一些有限的schedule方案,或者根据实际情况生成所以理论可行的schedule方案。
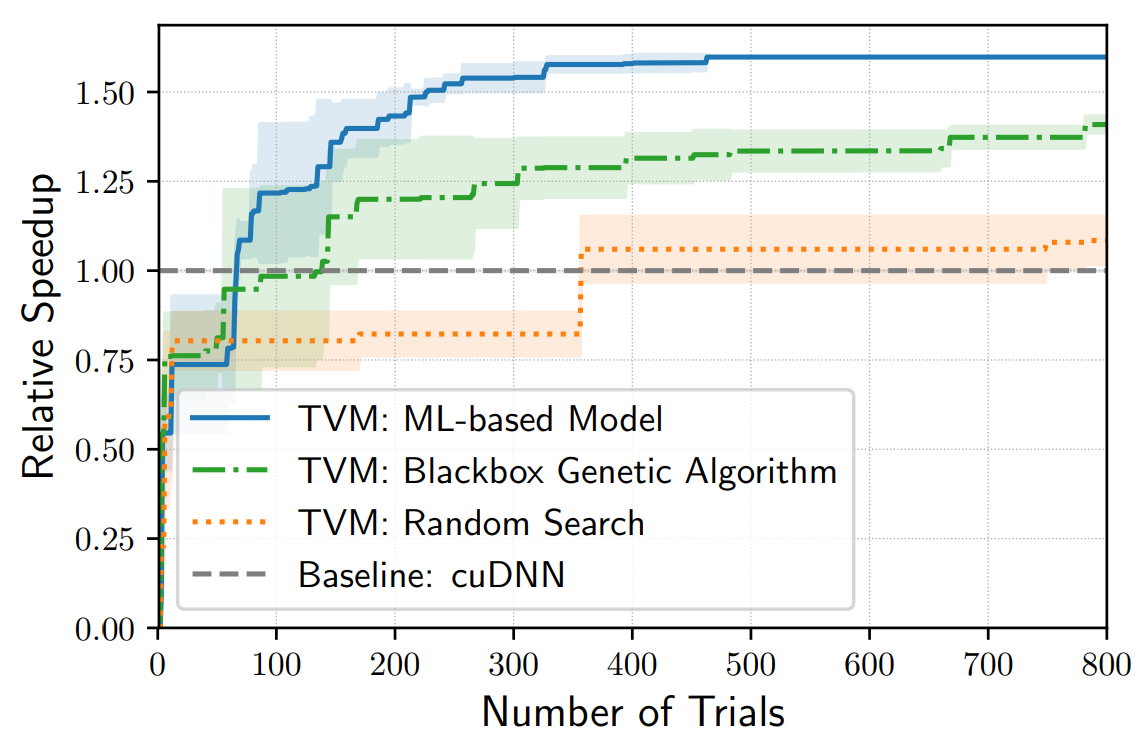
cost model相当于一个黑盒优化器,帮助我们在尽量少遍历各种schedule方案的情况下就能找到最优或者较优点(暴力搜索对于稍微深一些的网络可能就无能为力了),下图给出了TVM支持的一些常用搜索方案和使用CUDNN这个baseline的模型性能比较结果
下图给出了TVM和MXNet、Tensorflow的一些性能差异
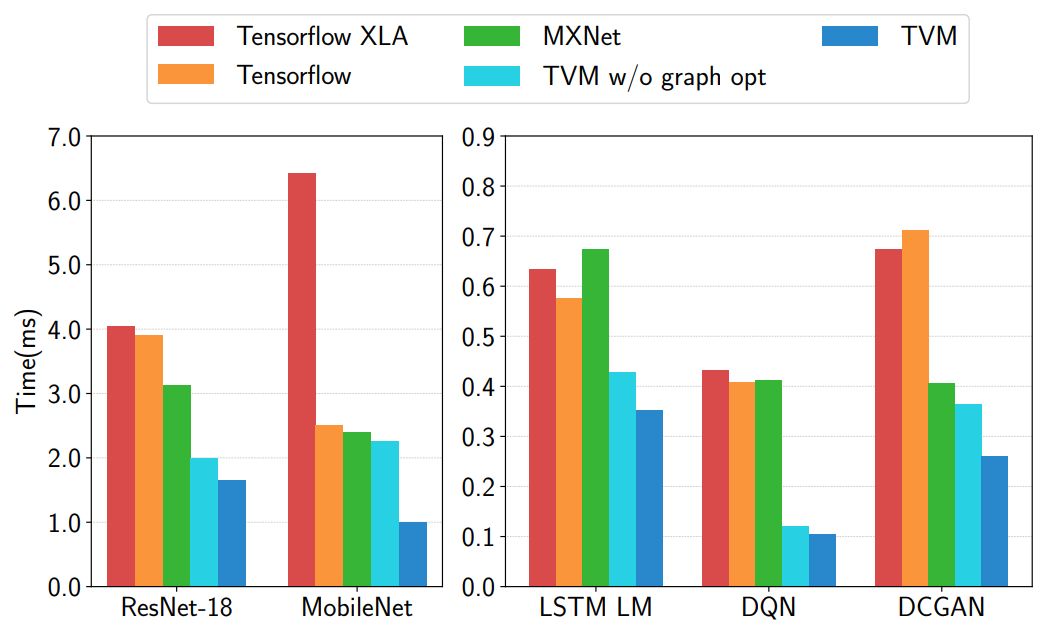
可以看到,TVM在使用自动优化搜索后对模型的加速还是非常可观的,并且比较对象基本都用了当前英伟达GPU平台最top级别的一些手工优化库(CUDNN)。
更多的实验结果可以看看论文的实验部分,TVM不管在服务端GPU、CPU还是移动端GPU、CPU,基本都是和当前最快的手工优化库性能持平甚至更加优秀。
网络调优实践
详细教程还请参考官方tutorial列表,这里只简单谈一下我在具体使用过程中遇到的一些坑:
- 如果要对比较深的神经网络(如resnet152)进行调优,建议把timeout设置大一点(如100s),否则很多尝试实际上都因为超时而拿不到结果,自然cost model学习到的信息也是不靠谱的;
- 如果网络比较复杂,n_trial也可以设置大一点,保证每一类setting都可以搜索充分;
- 如果使用nnvm作为计算图IR,并且把opt_level设置成3,则有可能会遇到模型编译完成以后预测结果和原始模型不一致的问题,这实际上是nnvm的bug,Tianqi大神在论坛上有回复,并建议使用TVM的第二代IR:
tvm.relay; - 原以为这个auto tuning应该是一个非常消耗GPU的操作,尤其是看到Scale up measurement by using multiple devices这一节的时候,想当然的觉得用多GPU卡能让这个搜索过程加速很多,实际运行了几次之后却发现大部分时间GPU都是空闲状态,真正制约整个过程的反而是CPU,所以,请尽量选择CPU核心数多一些的服务器;
