前一篇文章介绍了原始的GAN理论,包括后续提出的能够适用于更高分辨率的DCGAN在内,其模型本质都是训练一个生成器G,然后去不断欺骗一个也在实时更新的判别器D,虽然这个模型框架一定程度上非常好的解决了以往Generative Model需要非常多监督信息的弊端(例如Learning to Generate Chairs, Tables and Cars with Convolutional Networks),但是也具有一些不太好的缺陷:比如因为G的输入噪声完全不具有任何语义信息,因此即使在允许使用一些类别label的情况下我们依然完全无法控制生成的样本是什么样子;除了使用一些限制生成样本diversity的regularization手段,如何保证生成器真的可以生成数据集中尽可能多的样本类型?如果我们的数据集是带有一些已标注label的,该如何融入模型以达到更好的效果?服从不同概率分布的G的输入噪声会对最终生成的图像产生怎样的影响?对于某个特定的数据集是否有一个最优的噪声概率分布?
由University of Toronto、Google Brain和OpenAI合作的文章Adversarial Autoencoders(AAE)提出了一个使用Autoencoder进行对抗学习的idea,某种程度上对之前这些问题提供了一些新思路,并且包含了Unsupervised、Semi-Supervised和Supervised三种formulation。这篇文章其实自己已经看了有挺长一段时间,不过由于在和另一篇InfoGAN做对比以及实验复现过程中花了较多的时间,因此直到现在才写下了这篇文章,MXNet的代码实现请点这里。
无监督学习(Unsupervised)
Adversarial Autoencoders的核心仍然是利用一个生成器G和一个判别器D进行对抗学习,以区分real data和fake data,但是差别在于这里需要判别真假的data并不是自然图像,而是一个编码向量z,对应的real data和fake data分别由autoencoder中的encoder和一个预定义的随机概率分布生成,最后用于image generation的网络也并非是之前的生成器G,而是autoencoder中的decoder,模型架构如下图所示: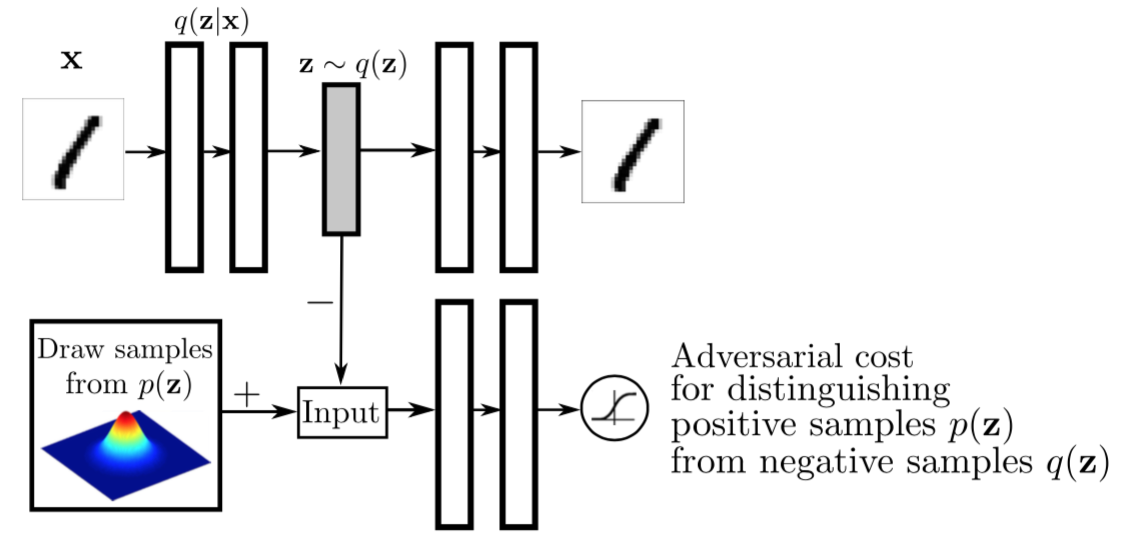
x表示自然图像数据,我们会把它输入一个正常的autoencoder,让encoder对其编码,生成一个latent variable z(这里假设该变量满足概率分布q(z)),然后decoder会尝试对这个latent variable进行解码,重新生成图片数据 \(\hat{x}\) ,loss函数就是普通autoencoder使用的重构误差函数,linear regression(图片数据为0-255之间)或者logistic regression(图片数据scale到0-1之间)。模型到这里其实还只是一个普通的自编码器,真正重要的地方在于由充当生成器G的编码器和下方判别器D组成的对抗网络,此处G和D联系起来的不再是图片数据,而是一个一维向量z,判别器D通过不断学习,预测输入的z来自于real data(服从q(z)概率分布)还是fake data(服从预定义的p(z)概率分布)。由于这里的p(z)可以是任何我们可以生成的一个概率分布,因此整个对抗学习过程实际上可以认为是通过调整encoder不断让其产生数据的概率分布q(z)接近我们预定义的p(z),当模型训练完成后,由于p(z)与q(z)十分相近,因此可以直接通过p(z)产生我们需要的随机latent variable,然后借助于解码器产生一个新的图像数据。
具体的模型训练主要分成两步:
- 自编码器的重构图像,使decoder能够从encoder生成的编码数据恢复出原始图像内容;
- 生成器和判别器的对抗学习,这里首先训练判别器D来区分输入的编码向量z来自q(z)还是p(z),然后训练生成器(编码器)生成更加接近p(z)的q(z)来欺骗判别器D。
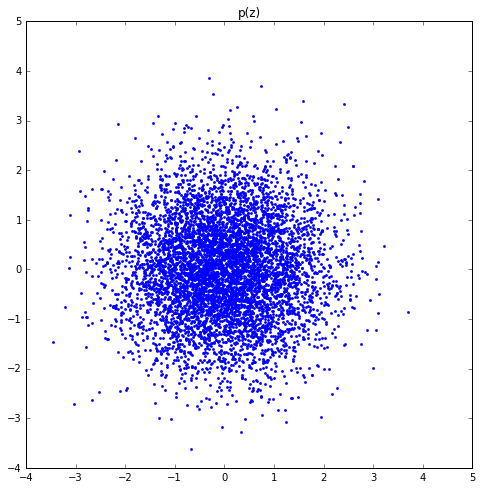
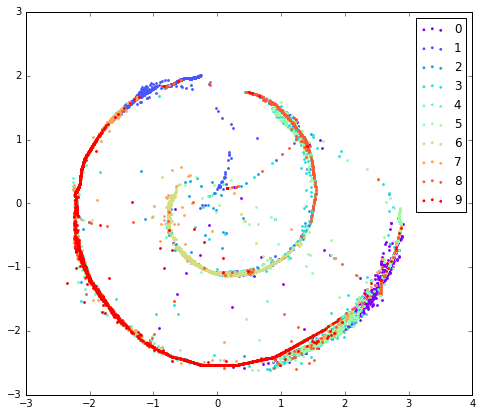
值得注意的是,由于MNIST手写数字本身比较简单,然后为了方便可视化,作者在实验中选择的z的维度只有2,因此可以很方便的把p(z)、q(z)和最终生成的图片样本全都可视化出来。另外,文中选择的几个预定义p(z)有single gaussian、10 gaussian mixture、swiss roll,我在自己的MXNet代码实现中产生的几个q(z)和p(z)结果如下:
- Single Gaussian:
- 10 Gaussian Mixture:

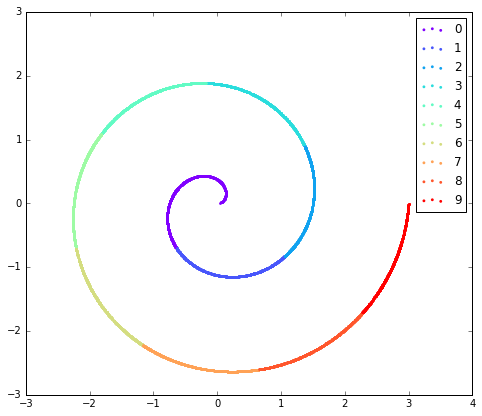
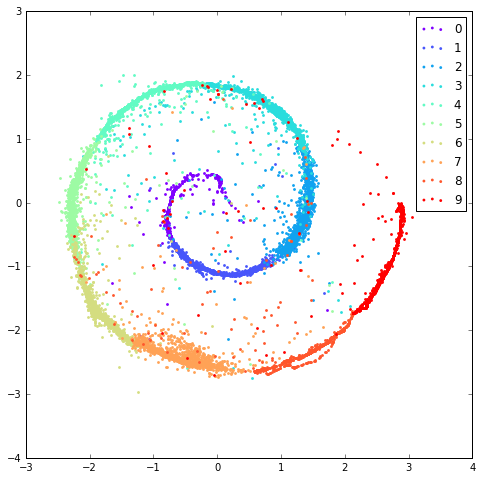
- Swiss Roll:

- Uniform:
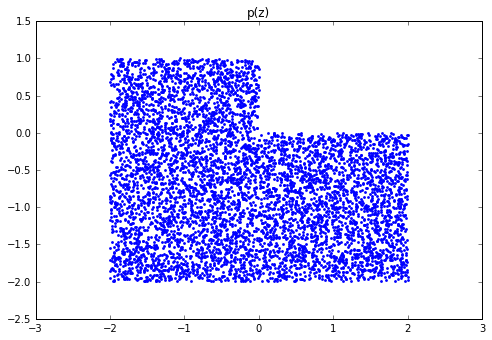
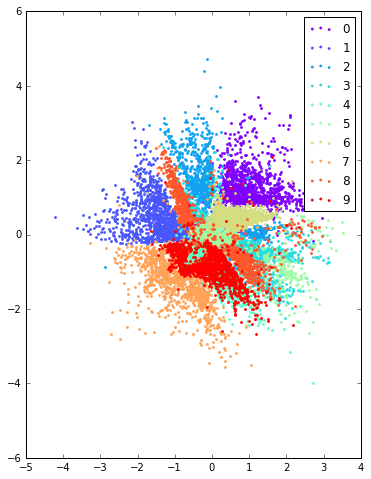
可以看出,在无监督学习任务中,虽然没有输入任何手写数字数据的标签信息,但是各个类别的样本最终形成的概率分布还是呈现了一定的聚集效果,类似于使用聚类方法。
融入标签数据(Supervised Learning)
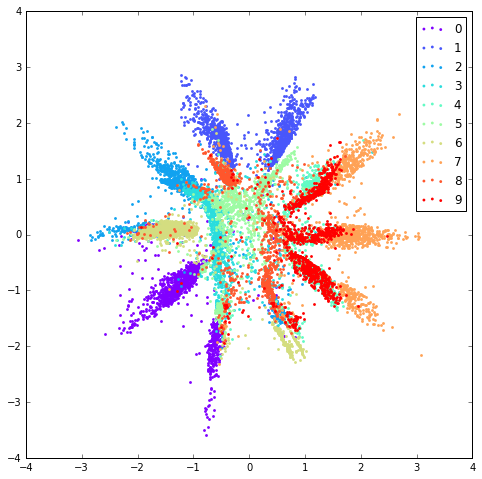
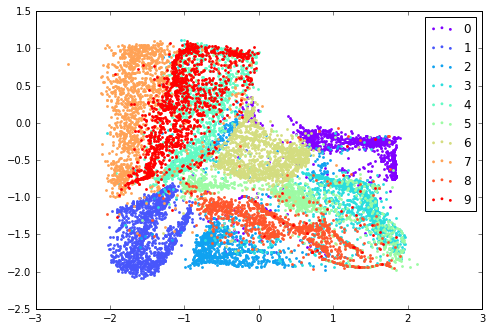
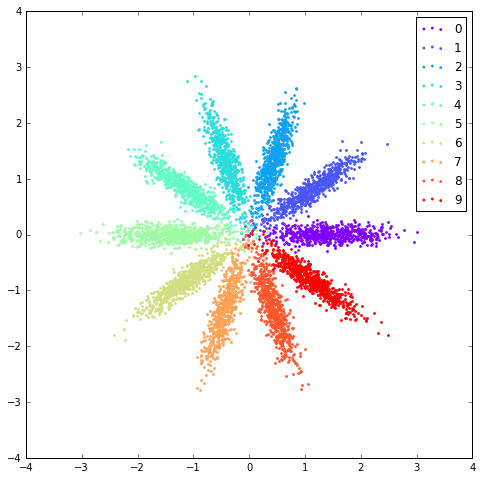
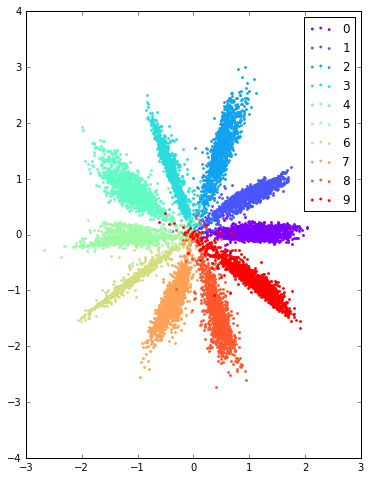
前面提到了原始GAN模型另外一个问题就是无法很好的利用数据标签信息,这里,AAE对此提供了一个很不错的解决办法,即为判别器额外增加一个one hot输入,该输入代表了样本的类别信息,在MNIST数据中,这个label就是图片所代表的数字,当然,仅仅为real data增加label显然是不够的,我们还需要考虑fake data,因此作者提出根据数据的label我们也可以伪造出对应的z,比如在采用10 gaussian mixture时,我们对于第零个gaussian产生的样本全部标为0,一号gaussian产生的样本标为1,以此类推,模型训练初始阶段,由于fake data总是可以与对应的label对应上,而real data编码z与label则并无这样严格的对应关系,因此随着训练迭代,q(z)与label也会慢慢产生这样的对应关系,下方是加入了label信息后产生的结果图(仍然是q(z)、p(z)),注意,此时模型收敛后各个类别样本的聚集状况显然比之前Unsupervised Learning任务中好很多。
- 10 Gaussian Mixture:
- Swiss Roll:
- Uniform:
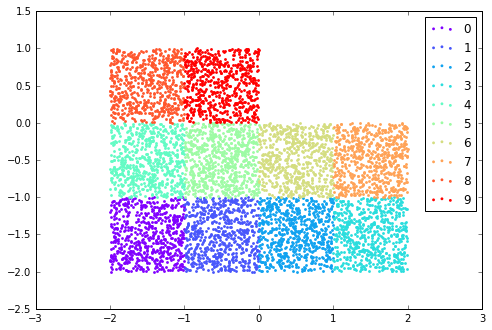
注意,由于单高斯分布不太适合产生label,因此在Supervised Learning任务中并没有被采用。
总结
其实文中还提到了AAE在Semi-Supervised Learning任务里的应用,方法是把Supervised Learning任务中的one hot向量维度改成n+1维,添加的一维用于表示所有unlabel的数据,对于fake data而言,此时的z就是在整个概率分布上产生,而非其中一部分,作者在论文里表示该方法可以使用很少量的有标注数据学习出非常棒的结果,不过由于时间关系自己在代码里没有完整实现,这里也不再赘述。
AAE相比原始GAN而言,显然具有了很多让生成结果更可控的特性,在论文中展示的结果非常不错,我自己在MNIST数据上通生成的图片结果也感觉比之前DCGAN产生的图片质量更高,如下图所示:

不过个人认为,由于Autoencoder本身在分辨率较高的自然图像数据上重构效果就不算太好,因此现阶段还很难把AAE扩展到高分辨率图片数据上,并且由于Decoder是以重构误差为目的进行训练,而非GAN那样以欺骗判别器为目的,因此可能更难生成非常sharp的新的图像。我在对自己实现的模型测试时,还选择了ImageNet和CelebA人脸数据,尝试生成64*64和128*128的图片,但是效果都比较一般,即是使用real data的编码向量z输入decoder,其生成的图像看起来也都边缘模糊,很多细节消失(DCGAN可能会随机产生细节,而不是粗暴的模糊化),远不如InfoGAN、Energy based GAN论文里给出的图像质量好,感觉像是autoencoder的瓶颈限制了AAE的最终效果,不过即使如此,AAE模型还是具有非常大的理论创新价值,对传统GAN理论提供了一个比较大的新formulation,相信后续也还会有很大的发展空间。
