从大四开始接触SVM时每次都是推公式从原始优化问题到对偶问题然后应用个KKT条件就完事,然后过了一段时间就又觉得不对,好像整个SVM过程还缺了一些东西,前段时间偶然间注意到了SVM的Sequential Minimal Optimization(SMO)优化,才突然反应过来是对偶问题最终求解拉格朗日乘子这一步以前总是被忽略掉。。。汗
首先简要回顾一下SVM问题的求解过程,以最简单的线性可分情况为例,
\[\min \frac{1}{2}\omega^T\omega\\\textit{s.t. }\forall y^i(\omega^Tx_i-b)\ge 1\]通过拉格朗日乘子定义一个拉格朗日函数
\[\mathbf{L}(\omega, b, \lambda) = \frac{1}{2}\omega^T\omega-\sum_{i=1}^n\lambda_i[y_i(\omega^Tx_i-b)-1]\]这里 \(\lambda=[\lambda_1, \lambda_2, \cdots, \lambda_n]^T\) ,原问题可化为
\[\min_{\omega, b}\max_{\lambda_i\ge 0}\mathbf{L}(\omega, b, \lambda)\]由于凸函数的对偶性,可以把前两个 \(\min\) 和 \(\max\) 调换顺序,原始问题最优解 \(p^*\) 和对偶问题最优解 \(d^*\) 相同
\[p^* = \min_{\omega, b}\max_{\lambda_i\ge 0}\mathbf{L}(\omega, b, \lambda) = \max_{\lambda_i\ge 0}\min_{\omega, b}\mathbf{L}(\omega, b, \lambda) = d^*\]对于上述对偶问题,即先对 \(\omega, b\) 求最小,然后再对 \(\lambda\) 求最大,根据KKT条件有
\[\frac{\partial\mathbf{L} }{\partial\omega} = \omega-\sum_{i=1}^n\lambda_iy_ix_i = 0\] \[\frac{\partial\mathbf{L} }{\partial b} = \sum_{i=1}^n\lambda_iy_i = 0\]代入对偶问题的目标函数中,得到
\[\max_{\lambda_i\ge 0}\min_{\omega, b}\mathbf{L}(\omega, b, \lambda) = \max_{\lambda_i\ge 0}\sum_{i=1}^n\lambda_i-\frac{1}{2}\sum_{i=1}^n\sum_{j=1}^n\lambda_i\lambda_jy_iy_jx_i^Tx_j\textit{, }\\\textit{s.t. }\lambda_i\ge 0\textit{, }\sum_{i=1}^n\lambda_iy_i=0\]这样,问题变成了只包含 \(\lambda\) 一个变量的二次规划(QP)问题,只要求出这些拉格朗日乘子的值,就能算出 \(\omega\) 和 \(b\) ,注意,上面这个QP问题的变量维数等于样本的数量n,意味着普通的二次规划算法并不能高效解决,在John C. Platt提出SMO的论文中有介绍几种之前被提出的方案,但都还不够优秀,主要是其中涉及的矩阵运算维数过大甚至放不进内存,SMO的提出有效避免了这种情况。
首先把上面的最大化问题转化成标准的最小化问题
\[\max_{\lambda_i\ge 0}\min_{\omega, b}\mathbf{L}(\omega, b, \lambda) = \min_{\lambda_i\ge 0}\frac{1}{2}\sum_{i=1}^n\sum_{j=1}^n\lambda_i\lambda_jy_iy_jx_i^Tx_j\textit{, }-\sum_{i=1}^n\lambda_i\\\textit{s.t. }\lambda_i\ge 0\textit{, }\sum_{i=1}^n\lambda_iy_i=0\](顺便提一句,如果是使用了soft margine的SVM,只需要在 \(\lambda_i\ge 0\) 的基础上再增加 \(\lambda_i \le C\) 约束条件即可,仍然属于标准的二次规划问题。)
SMO类似梯度下降算法,不断循环直到收敛,大体分为两个步骤:
- 选取两个参数 $$\lambda_i$$ 和 $$\lambda_j$$ ,在本次迭代中保持其他 $$\lambda_k$$ 不变;
- 优化目标函数,得到 $$\lambda_i$$ 和 $$\lambda_j$$ 的更新值
这里为什么每次迭代要选取两个参数作为优化参数呢?因为 \(\lambda\) 需要满足一个线性约束条件 \(\sum_{i=1}^n\lambda_iy_i=0\) ,如果每轮迭代只选取一个 \(\lambda_i\) ,那么通过这个约束条件可以直接利用其他 \(\lambda\) 的值算出 \(\lambda_i\) 来。与其他二次规划问题不同,这种只包含两个变量参数的SVM优化问题可以很容易的求出其解析解,不需要依赖数值优化算法求取近似解,因此每个循环迭代的更新效率非常高,整个算法运算速度也很快,而这一切,建立在两个关键问题的基础上:
- 求解包含两个参数二次规划问题的解析解。
- 如何选取两个参数 $$\lambda_i$$ 和 $$\lambda_j$$ ;
求解包含两个参数二次规划问题的解析解
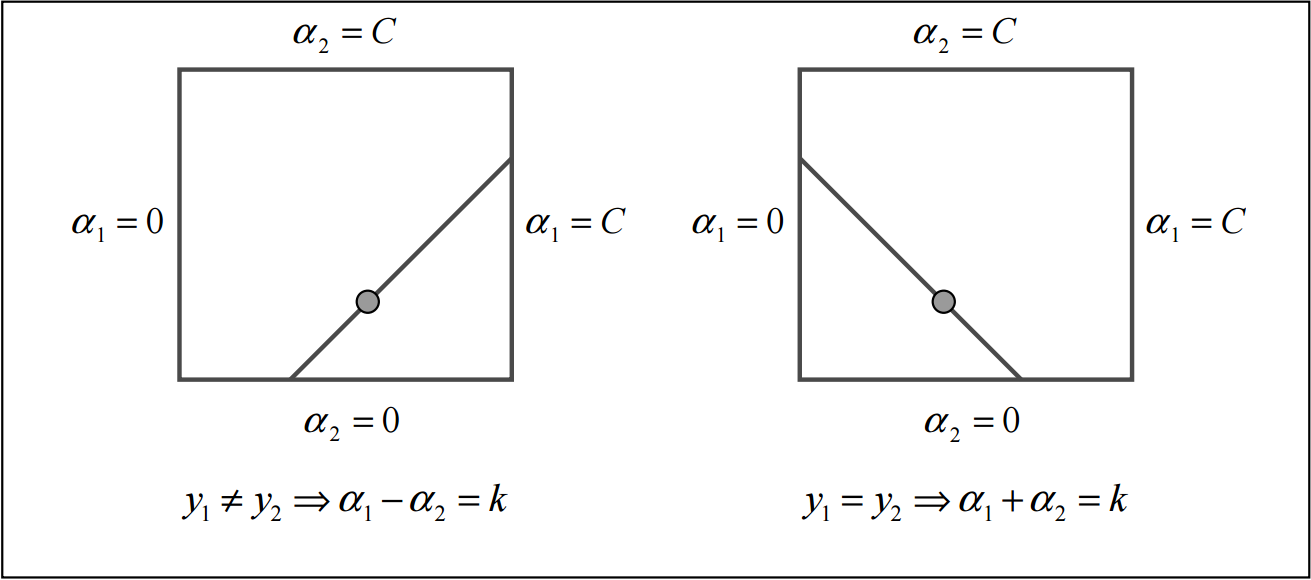
这里暂时假设soft margin系数为C,选取的是 \(\lambda_1\) 和 \(\lambda_2\) ,
\[y_1\lambda_1+y_2\lambda_2 = -\sum_{i=3}\lambda_iy_i, \lambda_1\ge 0, \lambda_2 \ge 0\]那么当 \(y_1=-y_2\) 时,必须满足
\[\lambda_1-\lambda_2=k\]因此可以得到 \(\lambda_2\) 的上下限 \((L, H)\) 为
\[L = max(0, \lambda_2-\lambda_1)\] \[H = min(C, C+\lambda_2-\lambda_1)\]如果 \(y_1=y_2\) ,则
\[L = max(0, \lambda_2+\lambda_1-C)\] \[H = min(C, \lambda_2+\lambda_1)\]考虑到具体数学推到实在复杂(抄公式抄到累死。。。),此处省略公式一万行,简要概括就是把目标函数里的 \(\lambda_1\) 用 \(\lambda_2\) 替换,然后变成了一个只有变量 \(\lambda_2\) 的二次函数,其极值点为导数等于0的点
\[\lambda_2^{\textit{new} } = \lambda_2^{\textit{old} }+\frac{y_2(E_1-E_2)}{\eta}\]其中 \(\eta\) 是目标函数关于 \(\lambda_2\) 的二阶偏导, \(E_i=\omega^Tx_i-b-y_i\) 是训练样本上的error。
此时,在 \((L, H)\) 间求其极小值就变成了一个初等数学问题(判断极值点在边界左边、内部、右边三种情况)。
启发式(heuristic)选取两个参数
原论文里在参数选择这一section的开头提到”As long as SMO always optimizes and alters two Lagrange multipliers at every step and at least one of the Lagrange multipliers violated the KKT conditions before the step, then each step will decrease the objective function according to Osuna’s theorem. Convergence is thus guaranteed.” 也就是说,在不断的循环迭代过程中,只要每次优化步骤之前存在某个拉格朗日乘子对应的一项违反了KKT条件,那么目标函数总会不断减小,最终达到收敛。
具体来说:
- 第一轮迭代我们首先遍历所有样本,挑选违反KKT条件的 \(\lambda_i\) 作为 \(\lambda_1\) ;
- 在其他所有拉格朗日乘子中选取最大化 \(|E_2-E_1|\) 的那个作为 \(\lambda_2\) ,执行两变量优化过程;
- 在所有非边界样本( \(0<\lambda_i<C\) )中寻找违反KKT条件的拉格朗日乘子作为 \(\lambda_1\) ,执行步骤2;若不存在,说明收敛条件已经满足,退出循环。
总结
SVM基本是所有接触机器学习的人最先接触到的几种分类器之一,其地位也是重中之重,刚开始学习时最烦恼的可能是各种数学公式,完全没有精力思考其内在原理,后来逐渐体会到各个关键步骤为何要采用对应的步骤去解决,比如为什么要变换成对偶问题而不是直接求解原问题,解对偶问题时 \(\omega, b\) 是通过令偏导数为0获得,那为什么 \(\lambda\) 不能也这么计算等等。SMO算法被用在解决SVM最后最关键的拉格朗日乘子计算问题这么多年来一直没有被替换,可见其经典,但是相对与SVM内部原理的简单,却又显得有些复杂,不知道SVM在经历这么多代人研究后在未来还能不能有新的突破。
