在优化问题中,很多求解方法都需要利用到目标函数的梯度信息,比如梯度下降法(gradient descent),但是在实际情况中,经常会碰到不可导的情况,这时就需要用到次梯度(Subgradient)这个概念了。
官方定义就不抄了,大致就是:
\(\mathbf{g}\) is a subgradient of \(\mathbf{f}\) (convex or not) at \(x\) if
\[f(y) \ge f(x)+g^T(y-x), \forall y\]这里主要包含两层意思:1.用次梯度对原函数做出的一阶展开估计总是比真实值要小;2.次梯度可能不唯一。
实际上,函数 \(f(x)\) 在 \(x\) 处的次梯度可以构成一个集合,通常用符号 \(\partial f(x)\) 表示,这个集合是一个凸集,元素个数可能等于0或者大于0。
如果 \(f(x)\) 为凸函数,那么 \(\partial f(x)\) 非空,如果它还在整个定义域上可导,那么 \(\partial f(x) = \{\nabla f(x)\}\) ,这就意味着:
\(\partial f(x)\) 仅含有一个元素 \(g \leftrightarrow?g=\nabla f(x)\) 且 \(f(x)\) 在x处可导
我们知道对于任意一个凸函数,其局部最小值就是全局最小值,并且该最小值点的导数为0,那么对于一个不要求必须可导的凸函数的次导数而言,有
\[f(x^*)=\min_{x}f(x) \leftrightarrow 0\in \partial f(x^*)\]OK,终于可以开始正题了,经典梯度下降算法实际上是利用负梯度总是指向最小值点这一性质,然后每次迭代 \(x^{k+1}=x^k-\alpha_k\nabla f(x^k)\) , \(\alpha_k\) 是一个很小的控制步进长度的数,可以是常量也可以是变量,迭代过程一直进行直到收敛。
那么对于次梯度,我们可以采用同样简单的迭代方式来求解最小值点吗?非常幸运,答案是可以,不过原因却并非梯度下降法的理论依据这么简单,因为次梯度不一定指向最小值点的方向(通常不指向。。。如下图),但是,这个方向可以让你离最小值点更近
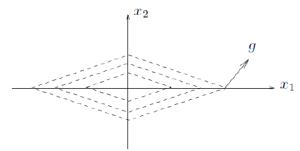
证明如下:
假设 \(x^*\) 是最小值点,g为 \(\partial f(x)\) 集合中的一个元素,当前我们的位置是 \(x_1\) ,那么当前位置和目的地的距离是 \(\|x_1-z\|^2\) ,经过一次迭代 \(x_2=x_1-\alpha g\) ,离目的地的距离变成 \(\|x_2-x^*\|^2\)
\[\begin{split} \|x_1-\alpha g-x^*\|^2 &= \|x_1-x^*\|^2 -2\alpha g^T(x_1-x^*)+\alpha^2\|g\|^2\\&\le \|x_1-x^*\|^2 -2\alpha (f(x_1)-f(x^*))+\alpha^2\|g\|^2\\&\le\|x_1-x^*\|^2\end{split}\]也就是说只要不停的迭代下去,这个距离总会不停的下降!至于最终是否一定会下降到最小值点以及收敛的速率请自行查找详细资料,这里不抄公式了。
另外,因为次梯度通常不唯一,而上面并没有提到任何次梯度的选取,因此理论上,任选一个都是可以使坐标不断向最小值点靠近,只是收敛的速率会不一样,下面是利用Subgradient method求解最优化问题的详细描述:
\(f\) is convex and non-differentiable: minimize \(f(x)\)
Subgradient method: \(x^{k+1} = x^k-\alpha_k g^k\)
- \(x^k\) is the \(k\) th iterate
- \(g^k\) is any subgradient of \(f\) at \(x^k\)
- \(\alpha_k > 0\) is the \(k\) th step size
有了这个,当然也就可以把gradient decent的各种实现方法套进来,比如batch subgradient decent或者stochastic subgradient descent,这里不再赘述。
